If you’re diving into the Harvard Fundamentals of TinyML course, you’ve likely realized that this field isn't just about cool AI models—it’s about the marriage of machine learning and embedded systems.
As Professor Vijay Reddi points out, to master TinyML, we first have to understand the "box" we’re building in.
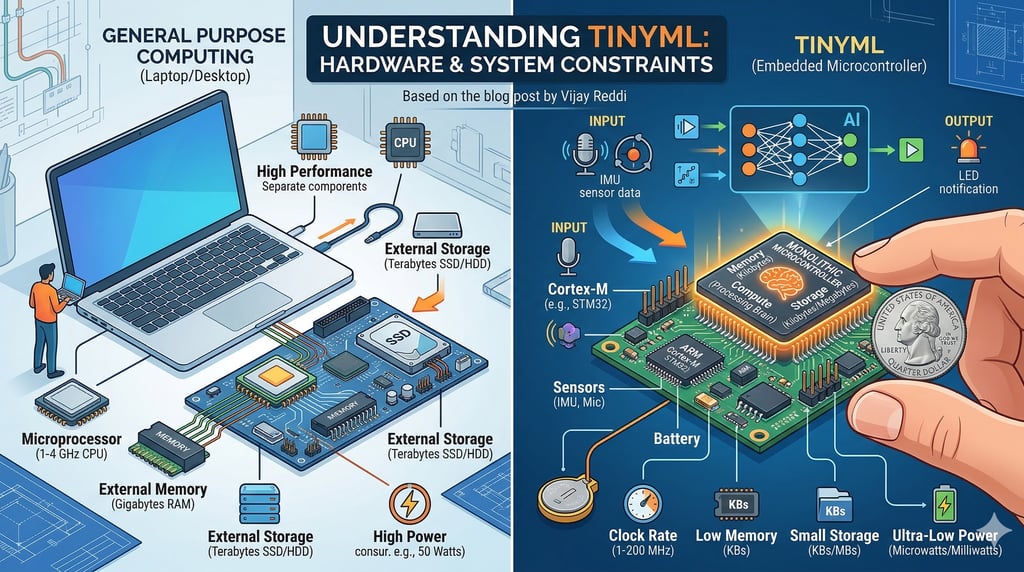
Microprocessors vs. Microcontrollers
Most of us are used to microprocessors—the brains in our laptops. These are modular; you can swap out RAM or upgrade a hard drive. They are built for general-purpose tasks and high performance.
Microcontrollers, however, are the heart of TinyML. They are "monolithic blocks" where the processor, memory (RAM), and storage are all fused into one tiny chip. You don't get to cherry-pick parts; you get what’s in the package.
The "Tiny" Reality Check
The scale of difference here is mind-blowing. When we talk about these embedded systems, we are moving from a world of "Gigas" to a world of "Kilos."
FeatureMicroprocessor (Laptop)Microcontroller (TinyML)Clock Speed1–4 GHz1–200+ MHzMemory (RAM)Megabytes to GigabytesKilobytesStorageGigabytes to TerabytesKilobytes to MegabytesPower10s of WattsMicrowatts to Milliwatts
Why This Matters
Working with such tight constraints changes how we approach AI. You have to ask yourself:
How complex is the task? Can it actually run on a chip with only 256KB of RAM?
What is the power budget? Is this running on a tiny battery for years, or just intermittently?
The beauty of TinyML lies in these constraints. Once you understand the limits of the hardware, you can start building "intelligence" that is ubiquitous, invisible, and incredibly efficient. It’s about doing more with significantly less!